 ElasticSearch基础
ElasticSearch基础
# 1 核心概念
# 1.1 索引 index
一个索引就是一个拥有几分相似特征的文档的集合。比如说,可以有一个客户数据的索引,另一个产品目录的索引,还有一个订单数据的索引。 一个索引由一个名字来标识(必须全部是小写字母的),并且当我们要对对应于这个索引中的文档进行索引、搜索、更新和删除的时候,都要使用到这个名字。
# 1.2 映射 mapping
ElasticSearch中的映射(Mapping)用来定义一个文档。类似数据库中的表结构定义。 mapping是处理数据的方式和规则方面做一些限制,如某个字段的数据类型、默认值、分词器、是否被索引等等,这些都是映射里面可以设置的。
# 1.3 字段Field
相当于是数据表的字段|列。
# 1.4 字段类型 Type
每一个字段都应该有一个对应的类型,例如:Text、Keyword、Byte等。
# 1.5 文档 document
一个文档是一个可被索引的基础信息单元,类似一条记录。文档以JSON (Javascript Object Notation)格式来表示。
# 1.6 集群 cluster
一个集群就是由一个或多个节点组织在一起,它们共同持有整个的数据,并一起提供索引和搜索功能。
# 1.7 节点 node
一个节点是集群中的一个服务器,作为集群的一部分,它存储数据,参与集群的索引和搜索功能。
一个节点可以通过配置集群名称的方式来加入一个指定的集群。默认情况下,每个节点都会被安排加入到一个叫做elasticsearch的集群中。
提示
这意味着,如果在网络中启动了若干个节点,并假定它们能够相互发现彼此,它们将会加入到一个叫做elasticsearch的集群中在一个集群里,可以拥有任意多个节点。
而且,如果当前网络中没有运行任何Elasticsearch节点,这时启动一个节点,会默认创建并加入一个叫 做elasticsearch的集群。
# 1.8 分片和副本 shards&replicas
分片
一个索引可以存储超出单个结点硬件限制的大量数据。
提示
比如,一个具有10亿文档的索引占据1TB的磁盘空间,而任一节点都没有这样大的磁盘空间; 或者单个节点处理搜索请求,响应太慢。
为了解决这个问题,Elasticsearch提供了将索引划分成多份的能力,这些份就叫做分片。
当创建一个索引的时候,可以指定你想要的分片的数量,每个分片本身也是一个功能完善并且独立的“索引”,这个“索引”可以被放置到集群中的任何节点上。
分片很重要,主要有两方面的原因 允许水平分割/扩展你的内容容量允许在分片之上进行分布式的、并行的操作,进而提高性能/吞吐量。
至于一个分片怎样分布,它的文档怎样聚合回搜索请求,是完全由Elasticsearch管理的,对于作为用户来说,这些都是透明的。
副本
在一个网络/云的环境里,失败随时都可能发生,在某个分片/节点不知怎么的就处于离线状态,或者由于任何原因消失了,这种情况下,有一个故障转移机制是非常有用并且是强烈推荐的。
为此目的,Elasticsearch允许你创建分片的一份或多份拷贝,这些拷贝叫做副本分片,或者直接叫副本。
副本之所以重要,有两个主要原因:
- 在分片/节点失败的情况下,提供了高可用性。 注意到复制分片从不与原/主要(original/primary)分片置于同一节点 上是非常重要的
- 扩展搜索量/吞吐量,因为搜索可以在所有的副本上并行运行 每个索引可以被分成多个分片。一个索引有0个或者多个副本 一旦设置了副本,每个索引就有了主分片和副本分片,分片和副本的数 量可以在索引创建的时候指定。在索引创建之后,可以在任何时候动态地改变副本的数量,但是不能改变分片的数量。
# 2 关于Index、Type、Document
# 2.1 含义
Index:索引。
Type:类型。
Document:文档。
文档是JSON类型的。
# 2.2 与MySQL类比
可以将 ES 中的这三个概念和 MySQL 类比
Index 对应 MySQL 中的 Database。
Type 对应 MySQL 中的 Table。
Document 对应 MySQL 中表的记录。
# 2.3 Type废弃
从ES 7.0 开始,Type 被废弃
在 7.0 以及之后的版本中 Type 被废弃了。
一个 index 中只有一个默认的 type,即 _doc。
ES 的 Type 被废弃后,库表合一,Index 既可以被认为对应 MySQL 的 Database,也可以认为对应 table。
也可以这样理解
ES 实例:对应 MySQL 实例中的一个 Database。
Index 对应 MySQL 中的 Table。
Document 对应 MySQL 中表的记录。
# 3 基本操作
# 3.1 创建索引
格式:PUT /索引名称
PUT /es_db
# 3.2 查询索引
格式:GET /索引名称
GET /es_db
# 3.3 删除索引
格式:DELETE /索引名称
DELETE /es_db
# 3.4 添加/修改文档
格式:PUT /索引名称/类型/id
PUT /es_db/_doc/1
{
"name":"louis",
"sex":1,
"age":18,
"address":"深圳",
"remark":"javadeveloper"
}
2
3
4
5
6
7
8
提示
通过调用 PUT /es_db/_doc ,系统会自动生成 document id
使用HTTP PUT /es_db/_create/1 创建时,URL中显示指定 _create ,此时如果改 ID 的文档已经存在,操作失败
PUT /es_db/_create/1
{
"name":"louis",
"sex":1,
"age":18,
"address":"深圳",
"remark":"javadeveloper"
}
2
3
4
5
6
7
8
# 3.5 删除文档
DELETE /es_db/_doc/1
# 3.6 批量查询操作
GET _mget
{
"docs": [
{
"_index": "es_db",
"_type": "_doc",
"_id": 1
},
{
"_index": "es_db",
"_type": "_doc",
"_id": 2
}
]
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
简化
GET /es_db/_doc/_mget
{
"docs": [
{
"_id": 1
},
{
"_id": 2
}
]
}
2
3
4
5
6
7
8
9
10
11
# 3.7 批量增删改操作
批量创建文档create
POST _bulk
{"create":{"_index":"es_db","_type":"_doc","_id":3}}
{"id":3,"title":"louis1","content":"louislouislouis1","tags":["java","es"]}
{"create":{"_index":"es_db","_type":"_doc","_id":4}}
{"id":4,"title":"louis2","content":"louislouislouis2","tags":["基础","es"]}
2
3
4
5
批量删除delete
POST _bulk
{"delete":{"_index":"es_db","_type":"_doc","_id":3}}
{"delete":{"_index":"es_db","_type":"_doc","_id":4}}
2
3
批量更新update
POST _bulk
{"update":{"_index":"es_db","_type":"_doc","_id":3}}
{"doc":{"content":"luo1"}}
{"update":{"_index":"es_db","_type":"_doc","_id":4}}
{"doc":{"content":"luo2"}}
2
3
4
5
# 4 DSL语言高级查询
提示
Domain Specific Language 领域专用语言
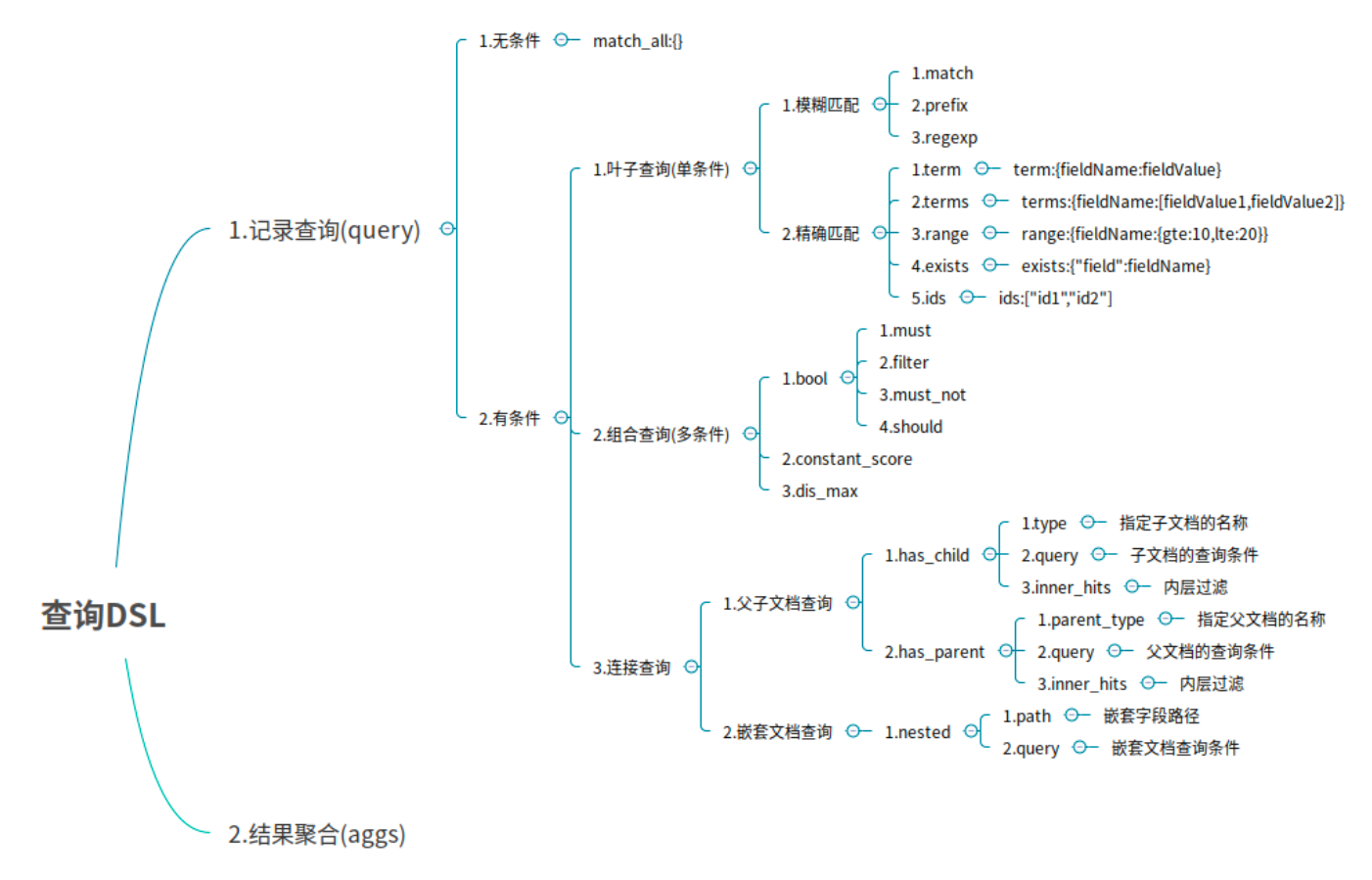
# 4.1 无查询条件
无查询条件是查询所有,默认是查询所有的,或者使用match_all表示所有。
GET /es_db/_doc/_search
GET /es_db/_doc/_search
{
"query": {
"match_all": {}
}
}
2
3
4
5
6
# 4.2 有查询条件
term 精确查询
POST /es_db/_doc/_search
{
"query": {
"term": {
"name": "louis"
}
}
}
2
3
4
5
6
7
8
等同于
select * from student where name = 'louis'
match 模糊查询
POST /es_db/_doc/_search
{
"from": 0,
"size": 2,
"query": {
"match": {
"name": "lou"
}
}
}
2
3
4
5
6
7
8
9
10
等同于
select * from user where name like '%lou%' limit 0, 2
multi_match 多字段模糊匹配查询与精准查询
POST /es_db/_doc/_search
{
"query": {
"multi_match": {
"query": "lou",
"fields": [
"address",
"name"
]
}
}
}
2
3
4
5
6
7
8
9
10
11
12
等同于
select * from student where name like '%lou%' or address like '%lou%'
query_string 未指定字段条件查询 , 含 AND 与 OR 条件
POST /es_db/_doc/_search
{
"query": {
"query_string": {
"query": "广州 OR 长沙"
}
}
}
2
3
4
5
6
7
8
query_string 指定字段条件查询 , 含 AND 与 OR 条件
POST /es_db/_doc/_search
{
"query": {
"query_string": {
"query": "admin OR 长沙",
"fields": [
"name",
"address"
]
}
}
}
2
3
4
5
6
7
8
9
10
11
12
范围查询
range 范围关键字
gte 大于等于
lte 小于等于
gt 大于
lt 小于
POST /es_db/_doc/_search
{
"query": {
"range": {
"age": {
"gte": 25,
"lte": 28
}
}
}
}
2
3
4
5
6
7
8
9
10
11
等同于
select * from user where age between 25 and 28
分页、输出字段、排序综合查询
POST /es_db/_doc/_search
{
"query": {
"range": {
"age": {
"gte": 25,
"lte": 28
}
}
},
"from": 0,
"size": 2,
"_source": [
"name",
"age",
"address"
],
"sort": {
"age": "desc"
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
Filter过滤器方式查询
提示
它的查询不会计算相关性分值,也不会对结果进行排序, 因此效率会高一点,查询的结果可以被缓存。
POST /es_db/_doc/_search
{
"query": {
"bool": {
"filter": {
"term": {
"age": 25
}
}
}
}
}
2
3
4
5
6
7
8
9
10
11
12
总结
1. match
模糊匹配,需要指定字段名,但是输入会进行分词,比如hello world会进行拆分为hello和world,然后匹配,如果字段中包含hello或者world,或者都包含的结果都会被查询出来,也就是说match是一个部分匹配的模糊查询。查询条件相对来说比较宽松。
2. term
这种查询和match在有些时候是等价的,比如我们查询单个的词hello,那么会和match查询结果一样,但是如果查询hello world,结果就相差很大,因为这个输入不会进行分词,就是说查询的时候,是查询字段分词结果中是否有hello world的字样,而不是查询字段中包含hello world的字样。当保存数据hello world时,elasticsearch会对字段内容进行分词,hello world会被分成hello和world,不存在hello world,因此这里的查询结果会为空。这也是term查询和match的区别。
3. match_phase
会对输入做分词,但是需要结果中也包含所有的分词,而且顺序要求一样。以hello world为例,要求结果中必须包含hello和world,而且还要求他们是连着的,顺序也是固定的,hello that world不满足,world hello也不满足条件。
4. query_string
和match类似,但是match需要指定字段名,query_string是所有字段搜索,范围更广泛。
# 5 聚合搜索
# 5.1 bucket和metric
bucket 就是一个聚合搜索时的数据分组。 如:
销售部门有员工张三和李四,开发部门有员工王五和赵六。那么根据部门分组聚合得到结果就是两个 bucket。
销售部门 bucket 中有张三和李四,开发部门 bucket 中有王五和赵六。
metric 就是对一个 bucket 数据执行的统计分析。如上述案例中,开发部门有2个员工,销售部门有2个员工,这就是 metric 。
metric 有多种统计,如:求和,最大值,最小值,平均值等。
示例
select count(*) from table group by column
group by column 分组后的每组数据就是 bucket 。 每个分组执行的 count(*) 就是 metric 。
GET /index_name/type_name/_search
{
"aggs" : {
"定义分组名称(最外层)": {
"分组策略如:terms、avg、sum" : {
"field" : "根据哪一个字段分组",
"其他参数" : ""
},
"aggs" : {
"分组名称1" : {},
"分组名称2" : {}
}
}
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
示例
size可以设置为0,表示不返回ES中的文档,只返回ES聚合之后的数据,提高查询速度,当然如果你需要这些文档的话,也可以按照实际情况进行设置
GET /cars/_search
{
"size": 0,
"aggs": {
"group_by_color": {
"terms": {
"field": "color"
},
"aggs": {
"group_by_brand": {
"terms": {
"field": "brand",
"order": {
"avg_by_price": "desc"
}
},
"aggs": {
"avg_by_price": {
"avg": {
"field": "price"
}
}
}
}
}
}
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
先根据color聚合分组,在组内根据price再次聚合分组,这种操作可以称为下钻分析。
{
"aggs": {
"group_by_color": {
"terms": {
"field": "color",
"order": {
"avg_by_price_color": "asc"
}
},
"aggs": {
"avg_by_price_color": {
"avg": {
"field": "price"
}
},
"group_by_brand": {
"terms": {
"field": "brand",
"order": {
"avg_by_price_brand": "desc"
}
},
"aggs": {
"avg_by_price_brand": {
"avg": {
"field": "price"
}
}
}
}
}
}
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35