 MySQL数据同步
MySQL数据同步
提示
详细部署步骤可查看:Canal数据同步 (opens new window)
# 1 canal
# 1.1 什么是canal?
canal是用java开发的基于数据库增量日志解析,提供增量数据订阅&消费的中间件。
目前,canal主要支持MySQL的binlog解析,解析完成才利用canal client用来处理获得的相关数据。数据库同步需要阿里的otter中间件,基于canal。
# 1.2 canal的工作原理?
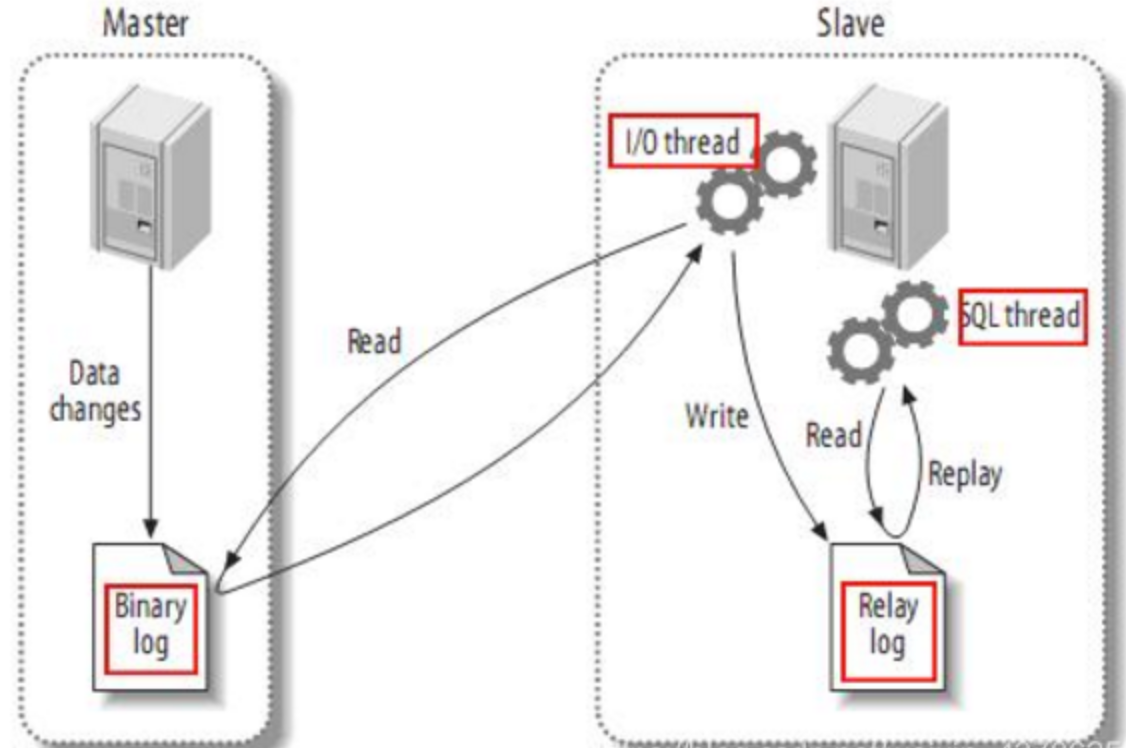
首先了解一下mysql主备复制原理:
(1)master主库将改变记录,发送到二进制文件(binary log)中
(2)slave从库向mysql Master发送dump协议,将master主库的binary log events拷贝到它的中继日志(relay log)
(3)slave从库读取并重做中继日志中的事件,将改变的数据同步到自己的数据库

canal的工作原理
把自己伪装成slave,从master复制数据。读取binlog是需要master授权的,因为binlog是加密的,授权分用户名密码才能读。
master授权后不知道读他的binlog的是从机还是canal,他的所有传输协议都符合从机的标准,所以master一直以为是从机读的。
# 1.3 canal高可用?
有两个canal服务器都监控一个或多个mysql服务器的binlog,这两个canal服务同时只能有一个提供服务。
当提供服务的这个宕机时,zookeeper能知道,zookeeper就通知另一个canal服务器让他提供服务。
当原来宕机的那个再启动起来时,是抢占模式的,谁抢到就谁上,没抢到就standy模式。
canal本身就是一个工具不存数据,宕机了就宕机,只有还有另外一个能提供服务就行,所以没有什么同步问题(不像数据库有同步问题)。
# 1.4 canal投递消息到kafka
1.canal投递消息到kafka,可指定mysql库表,支持按库表指定字段hash投递的kafka的partition。
2.canal投递到kafka的消息体,例如:
ConsumerRecord(topic = binlog, partition = 0, offset = 29, CreateTime = 1647331490778, serialized key size = -1, serialized value size = 52, headers = RecordHeaders(headers = [], isReadOnly = false), key = null, value = {"event":"datatest.user.update","value":[999,"ccc"]})
ConsumerRecord(topic = binlog, partition = 1, offset = 21, CreateTime = 1647331490777, serialized key size = -1, serialized value size = 62, headers = RecordHeaders(headers = [], isReadOnly = false), key = null, value = "{\"event\":\"datatest.user.update\",\"value\":[999,\"ccc\"]}")
ConsumerRecord(topic = binlog, partition = 0, offset = 30, CreateTime = 1647268549467, serialized key size = -1, serialized value size = 276, headers = RecordHeaders(headers = [], isReadOnly = false), key = null, value = {"data":[{"id":"999","name":"ccc"}],"database":"datatest","es":1647331490000,"id":8,"isDdl":false,"mysqlType":{"id":"int(11)","name":"varchar(50)"},"old":[{"name":"bbb"}],"pkNames":["id"],"sql":"","sqlType":{"id":4,"name":12},"table":"user","ts":1647268549466,"type":"UPDATE"})
# 2 mysql的binlog
# 2.1 什么是binlog?
mysql的二进制日志,记录了所有的DDL和DML(除了数据查询语句),以事件的形式进行记录,包含语句执行消耗的时间,mysql的二进制日志是事务安全型的。
开启二进制日志大概会有1%的性能损耗。
二进制日志有2个主要的使用场景:
① mysql的主备复制
② 数据恢复,通过使用mysqlbinlog工具来恢复数据
(用这个做恢复是备选方案,主方案还是定期快照,定期执行脚本导数据,其实就是把当前所有数据导成insert,这个量少)
二进制日志包括2类文件:
①二进制日志索引文件(后缀为.index)用于记录所有的二进制文件
②二进制日志文件(后缀为.00000*)记录数据库所有的DDL和DML(除了数据查询语句)
# 2.2 怎么开启binlog?
1.修改my.cnf配置

2.重启mysql

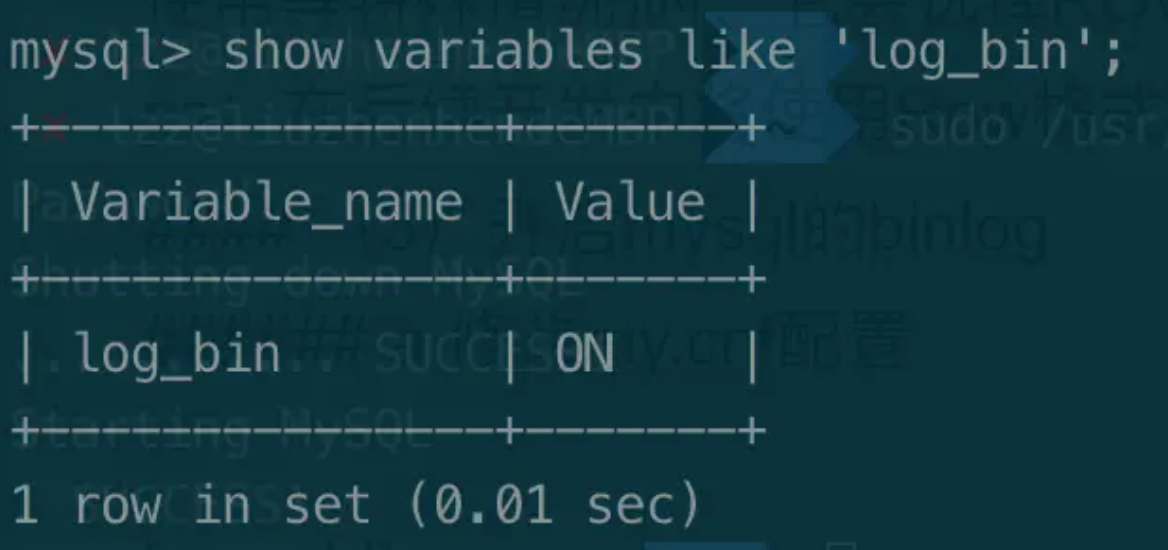
3.查看开启状态
输入 show variables like 'log_bin'; 查看binlog开启状态。如下图所示。
输入 show variables like 'binlog_format'; 查看Binary Log记录方式。如下图所示。

# 2.3 binlog有几种格式?
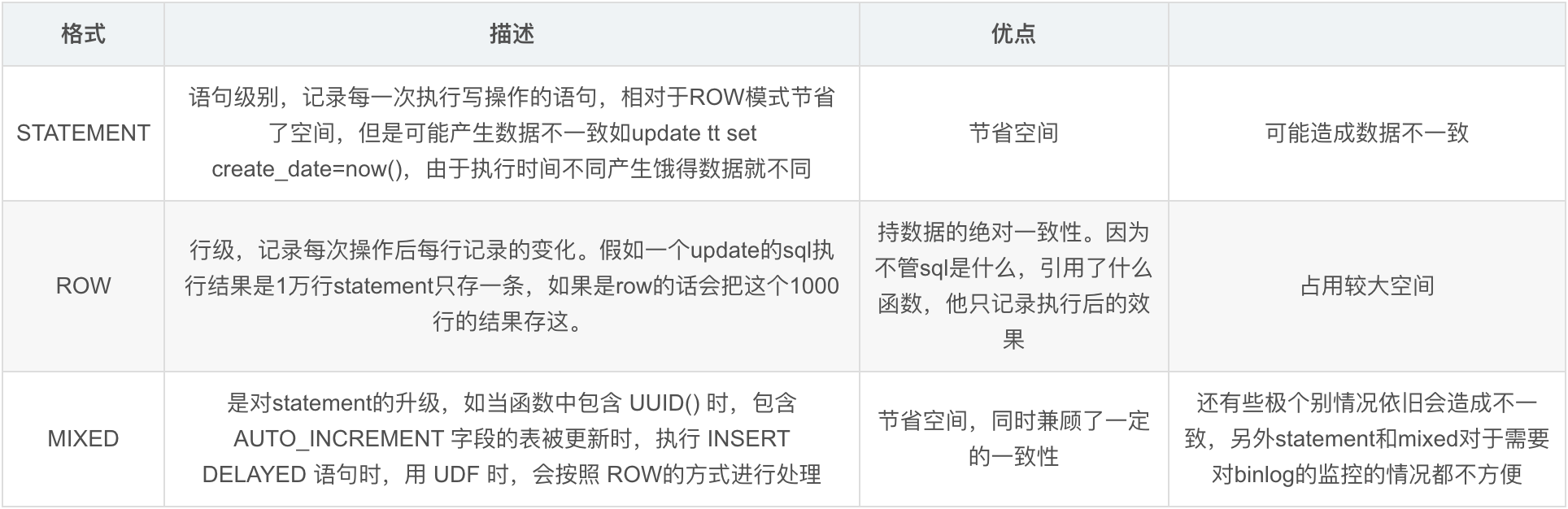
binlog的格式有三种:STATEMENT,MIXED,ROW对比如下
# 2.4 binlog格式怎么选择?
如果只考虑主从复制的话可以用mixed。
抽取数据用于统计分析之类的话用row。
# 3 Oracle GoldenGate(ogg)
# 3.1 什么是ogg?
GoldenGate软件是一种基于日志的结构化数据复制软件,它通过解析源数据库在线日志或归档日志获得数据的增量变化,再将这些变化应用到目标 数据库,从而实现源数据库与目标数据库同步。
GoldenGate可以实现一对一、广播(一对多)、聚合(多对一)、双向、点对点、级联等多种拓扑结构。
# 4 日志系统实现思路
1.业务入口生成唯一traceId -> 发送kafka落日志文件(包含此次操作的用户信息)
-> 数据变更落数据库(包含traceId)
2.binglog -> kafka -> 有traceId变更的数据解析落日志文件(包含本次变更的所有字段)
3.flume收集日志 -> kafka -> flink接收日志并清洗 -> 写入es(相同traceId关联成一条数据)