 Kafka
Kafka
# 1 通信模型

| 名称 | 解释 |
|---|---|
| Broker | 消息中间件处理节点,一个Kafka节点就是一个broker,一个或者多个Broker可以组成一个Kafka集群 |
| Topic | Kafka根据topic对消息进行归类,发布到Kafka集群的每条消息都需要指定一个topic |
| Partition | 物理上的概念,一个topic可以分为多个partition,每个partition内部消息是有序的 |
| Consumer | 消息消费者,从Broker读取消息的客户端 |
| ConsumerGroup | 每个Consumer属于一个特定的Consumer Group,一条消息可以被多个不同的Consumer Group消费,但是一个Consumer Group中只能有一个Consumer能够消费该消息 |
| Producer | 消息生产者,向Broker发送消息的客户端 |
# 2 概念
# 2.1 Topic & Partition
- 每个partition,都对应一个commit log文件。
- 每个partition都有一个唯一编号:offset。
- 每个consumer都是基于自己在commit log中的offset进行工作的。Offset由consumer自己维护。
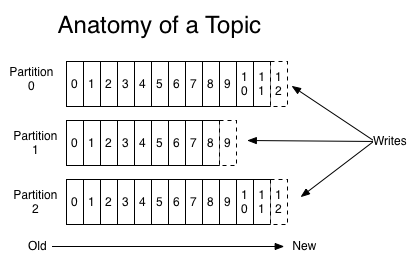
为什么topic数据要分区存储?
1、分区之后可以将不同的分区放在不同的机器上,相当于对数据做了分布式存储
2、提高并行度
数据存储:server.properties log.dirs=/usr/local/data/kafka-logs
Kafka Broker 有一个参数,log.segment.bytes,限定了每个日志段文件的大小,最大就是 1GB。
一个日志段文件满了,就自动开一个新的日志段文件来写入,避免单个文件过大,影响文件的读写性能,这个过程叫做 log rolling,正在被写入的那个日志段文件,叫做 active log segment。
# 2.2 Consumer & ConsumerGroup
- 一个partition同一个时刻在一个consumer group中只能有一个consumer在消费,从而保证消费顺序。
- consumer group中的consumer的数量不能比一个Topic中的partition的数量多,否则多出来的consumer消费不到消息。

Kafka只在partition的范围内保证消息消费的局部顺序性,不能在同一个topic中的多个partition中保证总的消费顺序性。
如果有在总体上保证消费顺序的需求,那么我们可以通过将topic的partition数量设置为1,将consumer group中的consumer instance数量也设置为1,但是这样会影响性能,所以kafka的顺序消费很少用。
# 2.3 Producer
写入方式
producer 采用 push 模式将消息发布到 broker,每条消息都是被append到patition中,属于顺序写磁盘
消息路由
producer发送消息到broker时,会根据分区算法选择将其存储到哪一个partition。其路由机制为:
1.指定了patition,则直接使用;
2.未指定patition 但指定key,通过对key的value进行hash选出一个patition。
3.patition和key都未指定,使用轮询选出一个patition。
消息确认机制
acks=0:表示producer不需要等待任何broker确认收到消息的回复,就可以继续发送下一条消息。
acks=1:至少要等待leader已经成功将数据写入本地log,但不需要等待所有follower是否成功写入。
acks=-1或all:leader需要等待所有备份(min.insync.replicas配置的备份个数)都成功写入日志
acks=-1时的数据流程:

1.producer先从zookeeper 的 "/brokers/.../state" 节点找到该partition的leader。
2.producer将消息发送给该leader。
3.leader将消息写入本地log。
4.followers从leader pull消息,写入本地log后向leader发送ACK。
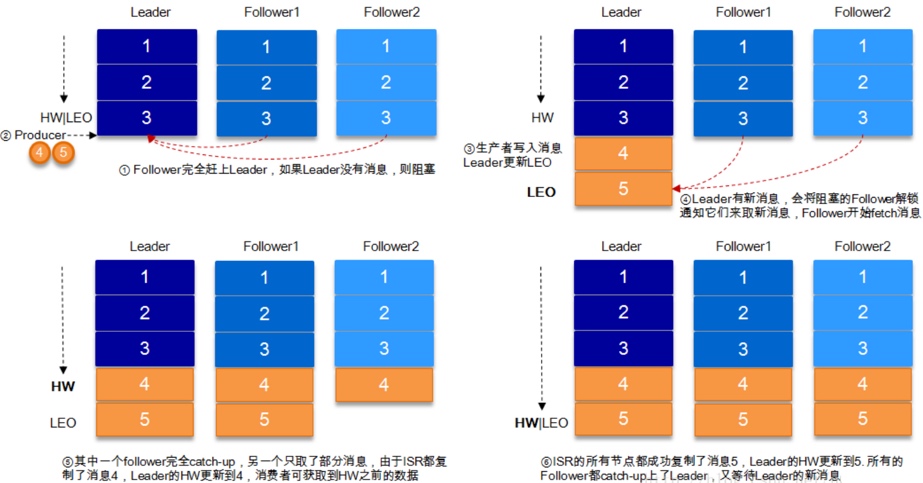
5.leader收到所有ISR中的replica的ACK后,增加HW(high watermark,最后 commit 的 offset)并向producer发送ACK。
# 3 选举机制
Controller选举机制
kafka集群启动的时候,会自动选举一台broker作为controller来管理整个集群,选举的过程是集群中每个broker都会尝试在zookeeper上创建一个 /controller 临时节点,zookeeper会保证有且仅有一个broker能创建成功,这个broker就会成为集群的总控器controller。
Partition副本选举Leader机制
controller感知到分区leader所在的broker挂了,会从ISR列表里挑第一个broker作为leader
(参数unclean.leader.election.enable=false的前提下。
参数unclean.leader.election.enable为true,则ISR列表里所有副本都挂了的时候可以在ISR列表外的副本中选leader,
这种设置,可以提高可用性,但是选出的新leader有可能数据少很多。)
副本进入ISR列表有两个条件:
1.必须能与zookeeper保持会话以及跟leader副本网络连通
2.副本能复制leader上的所有写操作,并且不能落后太多。(与leader副本同步滞后的副本,是由 replica.lag.time.max.ms配置决定的,超过这个时间都没有跟leader同步过的一次的副本会被移出ISR列表)
# 4 HW与LEO
LEO (Log End Offset)
HW有两个主要的作用:
1、用于实现副本备份机制(replication);
2、定义消息可见性,即HW之下的所有消息对consumer是可见的。如果没有HW机制,就需要其他手段来实现这两个功能。
# 5 kafka核心总控制器Controller
在Kafka集群中会有一个或者多个broker,其中有一个broker会被选举为控制器(Kafka Controller),它负责管理整个集群中所有分区和副本的状态。
主题管理
完成对Kafka主题的创建、删除以及分区增加的操作
分区重分配
对已有主题分区进行细粒度的分配功能
集群成员管理
自动检测新增Broker、Broker主动关闭、Broker宕机.
/brokers/ids/下面会存放Broker实例的id临时节点,当我们看到/brokers/ids下面有几个节点,就表示有多少个存活的Broker实例。
当Broker宕机时,临时节点就会被删除,此时控制器对应的监听器就会感知到Broker下线,进而完成对应的下线工作。
数据服务
向其它Broker提供数据服务,控制器上保存了最全的集群元数据信息,
其它Broker会定期接收控制器发来的元数据更新请求,从而更新其内存中的缓存数据
# 6 kafka高性能原因
# 6.1 磁盘顺序读写
kafka消息不能修改以及不会从文件中间删除保证了磁盘顺序读,kafka的消息写入文件都是追加在文件末尾。
# 6.2 PageCache
Kafka重度依赖底层操作系统提供的磁盘高速缓存PageCache(内核缓冲区)功能。
当上层有写操作时,操作系统只是将数据写入PageCache,同时标记Page属性为Dirty。内存池再异步地写到磁盘上。
当读操作发生时,先从PageCache中查找,如果发生缺页才进行磁盘调度,最终返回需要的数据。
实际上PageCache是把尽可能多的空闲内存都当做了磁盘缓存来使用。同时如果有其他进程申请内存,回收PageCache的代价又很小,所以现代的OS都支持PageCache。
# 6.3 零拷贝
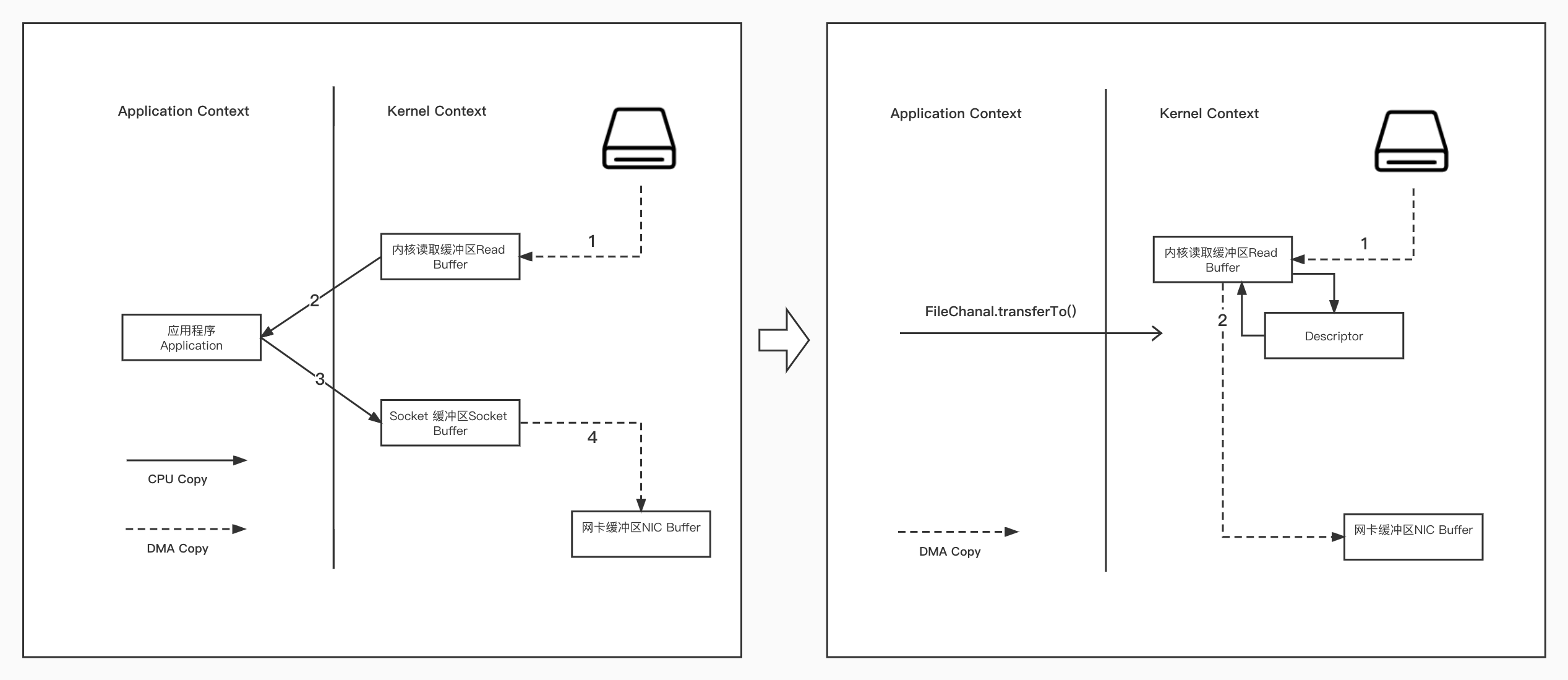
例:实际应用中,如果我们需要把磁盘中的某个文件内容发送到远程服务器上,那么它必须要经过几个拷贝的过程。
从磁盘中读取目标文件内容拷贝到
内核读取缓冲区。CPU控制器再把内核缓冲区的数据赋值到
用户空间的缓冲区中。应用程序中,调用
write()方法,把用户空间缓冲区中的数据拷贝到内核下的Socket Buffer中。内核模式下的Socket Buffer中的数据赋值到
网卡缓冲区(NIC Buffer)。最终,网卡缓冲区再把数据传输到目标服务器上。
总结
在这四次拷贝过程中,有两次拷贝是浪费的,分别是:
从内核空间赋值到用户空间
从用户空间再次赋值到内核空间
除此之外,用户空间和内核空间的切换会带来CPU的上下文切换,会对CPU性能造成影响。
零拷贝,就是把两次多余的拷贝省略掉,应用程序可以直接把磁盘中的数据从内核中直接传输给Socket,而不需要再经过应用程序所在的用户空间。
零拷贝通过
DMA(Direct Memory Access)技术把文件内容复制到内核空间的Read Buffer,接着把包含数据位置和长度的文件描述符加载到Socket Buffer中,DMA引擎直接把数据中内核空间传递给网卡设备。
在 Linux 中,零拷贝技术依赖于底层的
sendfile()方法实现。在 Java 中,
FileChannal.transferTo()方法的底层实现就是sendfile()方法。
除此之外,还有一个
mmap的文件映射机制原理是:将磁盘文件映射到内存,用户通过修改内存就能修改磁盘文件。使用这种方式可以获取I/O性能提升,省去了用户空间到内核空间复制的开销。
# 6.4 批量读写、批量压缩
Kafka的批量包括批量写入、批量发布等。它在消息投递时会将消息缓存起来,然后批量发送;同样,消费端在消费消息时,也不是一条一条处理的,而是批量进行拉取,提高了消息的处理速度。
Kafka的数据传输还可以配置压缩协议,比如
Gzip和Snappy压缩协议。虽然在进行数据压缩时会消耗少量的CPU资源,但可以减少网络传输的数据大小、优化网络IO、提升传输速率。
# 7 线上规划
