 分布式
分布式
# 1 RPC的工作过程
RPC(Remote Procedure Call)即远程过程调用,允许一台计算机调用另一台计算机上的程序得到结果,而代码中不需要做额外的编程,就像在本地调用一样。
现在互联网应用的量级越来越大,单台计算机的能力有限,需要借助可扩展的计算机集群来完成,分布式的应用可以借助RPC来完成机器之间的调用。
在RPC框架中主要有三个角色:Provider、Consumer和Registry。如下图所示:
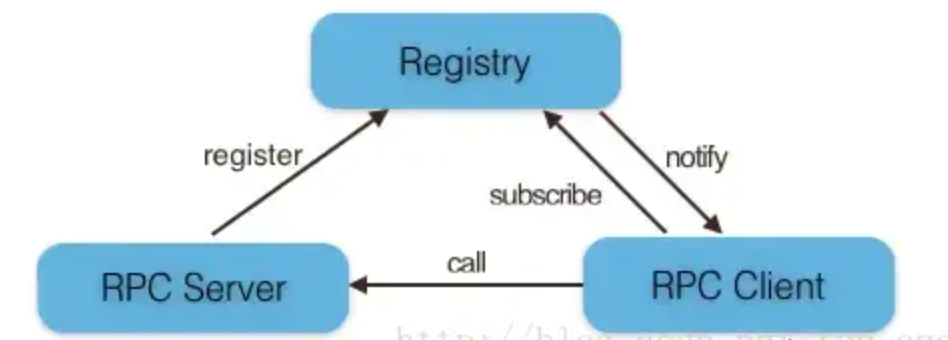
RPC调用流程:
1)服务消费方(client)调用以本地调用方式调用服务;
2)client stub接收到调用后负责将方法、参数等组装成能够进行网络传输的消息体;
3)client stub找到服务地址,并将消息发送到服务端;
4)server stub收到消息后进行解码;
5)server stub根据解码结果调用本地的服务;
6)本地服务执行并将结果返回给server stub;
7)server stub将返回结果打包成消息并发送至消费方;
8)client stub接收到消息,并进行解码;
9)服务消费方得到最终结果。
# 2 雪花算法
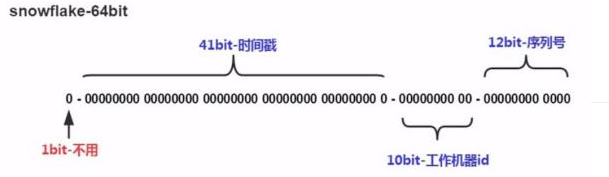
41bit时间戳:这里采用的就是当前系统的具体时间,单位为毫秒。
10bit工作机器ID(workerId):每台机器分配一个id,标示不同的机器,上限1024,标示一个集群某个业务最多部署的机器个数上限。
12bit序列号(自增域):表示在某一毫秒下,这个自增域最大可以分配的bit个数,在当前这种配置下,每一毫秒可以分配2^12个数据,也就是说QPS可以到 409.6 w/s。
# 2.1 存在问题
1.时间回拨问题:由于机器的时间是动态的调整的,有可能会出现时间跑到之前几毫秒(机器出现问题,时间可能回到之前),如果这个时候获取到了这种时间,则会出现数据重复。
2.机器id分配及回收问题:目前机器id需要每台机器不一样,这样的方式分配需要有方案进行处理,同时也要考虑,如果该机器宕机了,对应的workerId分配后的回收问题。
3.机器id上限:机器id是固定的bit,那么也就是对应的机器个数是有上限的,在有些业务场景下,需要所有机器共享同一个业务空间,那么10bit表示的1024台机器是不够的。
# 2.2 解决方案
1.延迟等待
将当前线程阻塞3ms,之后再获取时间,看时间是否⽐上⼀次请求的时间⼤。
如果⼤了,说明恢复正常了,则不⽤管。
如果还⼩,说明真出问题了,则抛出异常。
提示
「上一次请求时间」是在请求获取ID接口时,将「当前请求时间」赋值给「上一次请求时间」。
2.zookeeper或DB分配机器ID
采⽤zookeeper的顺序节点分配:解决了分配,回收可采⽤zookeeper临时节点回收,但是临时节点不可靠,存在⽆故消失问题。
采⽤DB中插⼊数据作为节点值:解决了分配,没有解决回收。
提示
目前工作中使用的是zookeeper方式。
3.改造雪花算法
提示
目前工作中的实现是将工作机器ID调整到12bit,序列号调整为10bit。
# 2.3 目前采用的方案

# 3 什么是跨域?跨域问题怎么解决?
协议、域名、端口号有一个不一样就是跨域。
跨域:跨域访问,简单来说就是A网站的javascript代码试图访问B网站,包括提交内容和获取内容。由于安全原因,跨域访问是被各大浏览器所默认禁止的。
目前我了解的解决跨域的几种方式:
1)手写过滤器
2)手写拦截器
3)jsonp
4)注解方式
5)配置nginx反向代理
共五种解决方式。
package com.louis.utils;
import java.io.IOException;
import javax.servlet.Filter;
import javax.servlet.FilterChain;
import javax.servlet.FilterConfig;
import javax.servlet.ServletException;
import javax.servlet.ServletRequest;
import javax.servlet.ServletResponse;
import javax.servlet.http.HttpServletRequest;
import javax.servlet.http.HttpServletResponse;
import org.slf4j.Logger;
import org.slf4j.LoggerFactory;
import org.springframework.stereotype.Component;
@Component
public class CrossFilter implements Filter {
private static Logger logger = LoggerFactory.getLogger(CrossFilter.class);
@Override
public void init(FilterConfig filterConfig) throws ServletException {
}
@Override
public void destroy() {
}
@Override
public void doFilter(ServletRequest request, ServletResponse response,
FilterChain chain) throws IOException, ServletException {
logger.debug("跨域请求进来了。。。");
HttpServletRequest httpServletRequest = (HttpServletRequest) request;
httpServletRequest.getSession();
HttpServletResponse httpResponse = (HttpServletResponse) response;
httpResponse.setHeader("Access-Control-Allow-Origin", "*");
httpResponse.setHeader("Access-Control-Allow-Methods", "*");
httpResponse.setHeader("Access-Control-Max-Age", "3600");
httpResponse.setHeader("Access-Control-Allow-Headers",
"Origin, X-Requested-With, Content-Type, Accept, Connection, User-Agent, Cookie");
httpResponse.setHeader("Access-Control-Allow-Credentials", "true");
httpResponse.setHeader("Content-type", "application/json");
httpResponse.setHeader("Cache-Control", "no-cache, must-revalidate");
chain.doFilter(request, httpResponse);
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
<!-- 添加过滤器过滤跨域请求 -->
<filter>
<filter-name>cors</filter-name>
<!-- 这里配置上面刚刚设置的java过滤器文件 -->
<filter-class>com.louis.utils.CrossFilter</filter-class>
</filter>
<filter-mapping>
<filter-name>cors</filter-name>
<!-- 这里配置你需要进行跨域的接口,*代表jsForSdp当前路径下所子有路径 -->
<url-pattern>/jsForSdp/*</url-pattern>
</filter-mapping>
2
3
4
5
6
7
8
9
10
11
也可以在springboot项目中配置一个ResourcesConfig资源配置类来解决跨域问题
@Configuration
public class ResourcesConfig implements WebMvcConfigurer {
/**
* 跨域配置
*/
@Bean
public CorsFilter corsFilter() {
UrlBasedCorsConfigurationSource source = new UrlBasedCorsConfigurationSource();
CorsConfiguration config = new CorsConfiguration();
config.setAllowCredentials(true);
// 设置访问源地址
config.addAllowedOrigin("*");
// 设置访问源请求头
config.addAllowedHeader("*");
// 设置访问源请求方法
config.addAllowedMethod("*");
// 对接口配置跨域设置
source.registerCorsConfiguration("/**", config);
return new CorsFilter(source);
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
# 4 CAP理论,Eureka与Zookeeper区别?
# 4.1 CAP 定义
一致性(Consistency)
数据在多个副本之间能够保持一致的特性(强一致性)。就像Redis的主从结构,Zookeeper的Master/Slave结构,主从之间的数据保持一致,这些都是最终一致性。
可用性(Availability)
系统一直处于可用状态,能正常响应数据,但是不保证响应数据为最新数据。
分区容错性(Partition tolerance)
分布式系统在遇到网络故障的时候,仍然能够对外提供满足一致性和可用性的服务,除非整个网络环境都发生了故障。
# 4.2 Eureka 与 Zookeeper
提示
CAP理论指出,一个分布式系统不可能同时满足C(一致性Consistency)、A(可用性Availability)和P(分区容错性Partition tolerance)。
由于分区容错性在是分布式系统中必须要保证的,因此我们只能在A和C之间进行权衡。
在此Zookeeper保证的是 CP, 而Eureka则是 AP。
- 当向注册中心查询服务列表时,我们可以容忍注册中心返回的是几分钟以前的注册信息,但不能接受服务直接down掉不可用。也就是说,服务注册功能对可用性的要求要高于一致性。
但是zk会出现这样一种情况,当master节点因为网络故障与其他节点失去联系时,剩余节点会重新进行leader选举。 问题在于,选举leader的时间太长,30 ~ 120s,且选举期间整个zk集群都是不可用的,这就导致在选举期间注册服务瘫痪。 - Eureka各个节点都是平等的,几个节点挂掉不会影响正常节点的工作,剩余的节点依然可以提供注册和查询服务。
而Eureka的客户端在向某个Eureka注册或时如果发现连接失败,则会自动切换至其它节点,只要有一台Eureka还在,就能保证注册服务可用(保证可用性),只不过查到的信息可能不是最新的(不保证强一致性)。
# 5 SOA和微服务架构的区别?
SOA (全称:Service Oriented Architecture) 面向服务的架构
一、架构划分不同
1、SOA强调按水平架构划分为:前、后端、数据库、测试等;
2、微服务强调按垂直架构划分,按业务能力划分,每个服务完成一种特定的功能,服务即产品。
二、技术平台选择不同
1、SOA应用倾向于使用统一的技术平台来解决所有问题;
2、微服务可以针对不同业务特征选择不同技术平台,去中心统一化,发挥各种技术平台的特长。
三、系统间边界处理机制不同
1、SOA架构强调的是异构系统之间的通信和解耦合;(一种粗粒度、松耦合的服务架构);
2、微服务架构强调的是系统按业务边界做细粒度的拆分和部署。
四、主要目标不同
1、SOA架构,主要目标是确保应用能够交互操作;
2、微服务架构,主要目标是实现新功能、并可以快速拓展开发团队。
# 6 分布式事务解决方案
# 6.1 两阶段提交(2PC)
什么是XA
XA是 X/Open DTP 组织(X/Open DTP group)定义的两阶段提交协议。
XA被许多数据库(如Oracle、DB2、SQL Server、MySQL)和中间件等工具(如CICS 和 Tuxedo)本地支持 。
XA就是X/Open DTP定义的交易中间件与数据库之间的接口规范(即接口函数),交易中间件用它来通知数据库事务的开始、结束以及提交、回滚等。
XA接口函数由数据库厂商提供。通常情况下,交易中间件与数据库通过XA 接口规范,使用两阶段提交来完成一个全局事务,XA规范的基础是 两阶段提交协议。
# 6.1.1 执行过程
- 第一阶段:询问各个事务数据源是否准备好。
- 第二阶段:真正将数据提交给事务数据源。
需引入一个协调者(Cooradinator)。其他的节点被称为参与者(Participant)。协调者负责调度参与者的行为,并最终决定这些参与者是否要把事务进行提交。
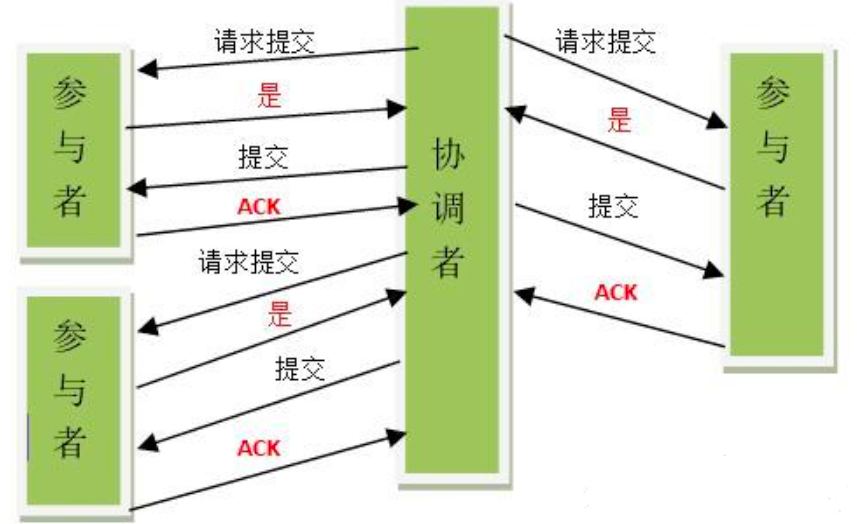
阶段一
- 协调者向所有参与者发送事务内容,询问是否可以提交事务,并等待答复。
- 各参与者执行事务操作,将undo和redo信息记入事务日志中(但不提交事务)。
- 如参与者执行成功,给协调者反馈yes,否则反馈no。
阶段二
如果协调者收到了参与者的失败消息或者超时,直接给每个参与者发送回滚(rollback)消息;
否则,发送提交(commit)消息。
- 当所有参与者均反馈yes,提交事务。
- 协调者向所有参与者发出正式提交事务的请求(commit请求)。
- 参与者执行commit请求,并释放整个事务期间占用的资源。
- 各参与者向协调者反馈ack(应答)完成的消息。
- 协调者收到所有参与者反馈的ack消息后,即完成事务提交。
- 当有一个参与者反馈no,回滚事务。
- 协调者向所有参与者发出回滚请求(即rollback请求)。
- 参与者使用阶段一中的undo信息执行回滚操作,并释放整个事务期间占用的资源。
- 各参与者向协调者反馈ack完成的信息。
- 协调者收到所有参与者反馈的ack消息后,即完成事务。
# 6.1.2 问题
- 性能问题:所有参与者在事务提交阶段处于同步阻塞状态,占用系统资源,容易导致性能瓶颈。
- 可靠性问题:如果协调者存在单点故障问题,或出现故障,提供者将一直处于锁定状态。
- 数据一致性问题:在阶段二中,如果出现协调者和参与者都挂了的情况,
# 6.1.3 优点
尽量保证了数据的强一致性,适合对数据强一致要求很高的关键领域。(其实也不能100%保证强一致)。
# 6.1.4 缺点
实现复杂,牺牲了可用性,对性能影响较大,不适合高并发高性能场景。
# 6.2 三阶段提交(3PC)
三阶段提交是在二阶段提交上的改进版本,3PC最关键要解决的就是协调者和参与者同时挂掉的问题,所以3PC把2PC的准备阶段再次一分为二,多了一个询问是否可以提交事务的步骤。
# 6.2.1 执行过程
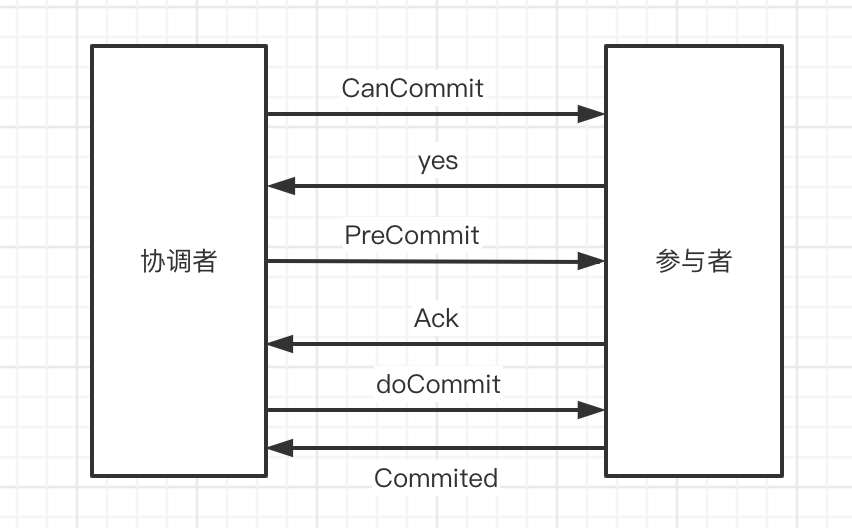
阶段一
- 协调者向所有参与者发出包含事务内容的canCommit请求,询问是否可以提交事务,并等待所有参与者答复。
- 参与者收到canCommit请求后,如果认为可以执行事务操作,则反馈yes并进入预备状态,否则反馈no。
阶段二
协调者根据参与者响应情况,有以下两种可能。
- 所有参与者均反馈yes,协调者预执行事务。
- 协调者向所有参与者发出preCommit请求,进入准备阶段。
- 参与者收到preCommit请求后,执行事务操作,将undo和redo信息记入事务日志中(但不提交事务)。
- 各参与者向协调者反馈ack响应或no响应,并等待最终指令。
- 只要有一个参与者反馈no,或者等待超时后协调者还无法收到所有提供者的反馈,则中断事务。
- 协调者向所有参与者发出abort请求。
- 无论收到协调者发出的abort请求,或者在等待协调者请求过程中出现超时,参与者均会中断事务。
阶段三
该阶段进行真正的事务提交,也可以分为以下两种情况。
- 所有参与者均反馈ack响应,执行真正的事务提交。
- 如果协调者处于工作状态,则向所有参与者发出do commit请求。
- 参与者收到do commit请求后,正式执行事务提交,并释放事务期间占用的资源。
- 各参与者向协调者反馈ack完成的消息。
- 协调者收到所有参与者反馈的ack消息后,即完成事务提交。
- 只要有一个参与者反馈no,或者等待超时后协调组还无法收到所有提供者的反馈,则回滚事务。
- 如果协调者处于工作状态,向所有参与者发出rollback请求。
- 参与者使用阶段一中的undo信息执行回滚操作,并释放整个事务期间占用的资源。
- 各参与者向协调者反馈ack完成的消息。
- 协调者收到所有参与者反馈的ack消息后,即完成事务回滚。
# 6.2.2 优点
相比二阶段提交,三阶段提交降低了阻塞范围,在等待超时后协调者或参与者会中断事务。避免了协调者单点问题。
# 6.2.3 缺点
数据不一致问题依然存在。
# 6.3 TCC(补偿事务)
TCC其实就是采用的补偿机制,核心思想是:针对每个操作,都要注册一个与其对应的确认和补偿(撤销)操作。
# 6.3.1 执行过程
分为三个步骤:
- Try 阶段主要是对业务系统做检测及资源预留。
- Confirm 阶段主要是对业务系统做确认提交,Try 阶段执行成功并开始执行 Confirm 阶段时,默认 Confirm 阶段是不会出错的。即:只要 Try 成功,Confirm 一定成功。
- Cancel 阶段主要是在业务执行错误,需要回滚的状态下执行的业务取消,预留资源释放。
示例:
假设小明要向小白转账,思路大概是:
- 首先在 Try 阶段,先调用接口把小明和小白的钱冻结起来。
- 在 Confirm 阶段,执行转账操作,转账成功进行解冻。
- 如果第2步执行成功,则转账成功。如果第2步执行失败,调用冻结接口对应的解冻方法(Cancel)。
# 6.3.2 优点
性能提升:锁的粒度变小,不会锁定整个资源。
数据最终一致性:保证事务最终完成确认或者取消。
可靠性:解决了XA协议的协调者单点故障问题,由业务方发起并控制业务活动。
# 6.3.3 缺点
TCC的 Try、Confirm 和 Cancel 操作功能要按具体业务来实现,业务耦合度较高,提高了开发成本。
# 6.4 本地消息表
本地消息表这种实现方式应该是业界使用最多的,其核心思想是将分布式事务拆分成本地事务进行处理。
# 6.4.1 执行过程
- 消息生产方,需要额外建一个消息表,并记录消息发送状态。消息表和业务数据在一个事务里提交,即在同一个数据库里面。然后消息会经过MQ发送到消息的消费方。如果消息发送失败,会进行重试发送。
- 消息消费方,需要处理这个消息,并完成自己的业务逻辑。如果业务上面处理失败,可以给生产方发送一个业务补偿消息,通知生产方进行回滚等操作。
- 定时器定时扫描本地消息表,把没处理完成的消息或失败的消息再发送一遍。
# 6.4.2 优点
非常经典的方案,比较简单,实现了最终一致性
# 6.4.3 缺点
消息表会耦合到业务系统中,如果没有封装好的解决方案,会有很多杂活需要处理。
# 6.5 MQ 事务消息
目前市面上有一些MQ是支持事务消息的,比如RocketMQ,他们支持的事务消息方式也是类似于二阶段提交。目前像RabbitMQ和Kafka都不支持事务消息。
提示
事务和事务消息是有区别的,事务保证的是两个操作的同时成功和失败,事务消息保证的是本地事务和发消息这两个动作的成功和失败。
# 6.5.1 执行过程
以RocketMQ为例,其思路大致为:
- 生产者将
半消息发送到 MQ Server。 - 发送返回成功后,执行本地事务。
- 根据本地事务的执行结果,将 commit 或 rollback 消息发送到 MQ Server。
- 如果在本地事务执行过程中缺少 commit/rollback 消息或生产者处于等待状态,MQ Server 将向同一组中的每个生产者发送检查消息,以获取事务状态。
- 生产者根据本地事务状态回复 commit/rollback 消息。 commit 的消息将传递给 consumer,但是 rollback 的消息将被 MQ Server 丢弃。
# 6.5.2 优点
实现了最终一致性,不需要依赖本地数据库事务。
# 6.5.3 缺点
实现难度大,主流MQ不支持,RocketMQ事务消息部分代码也未开源。